
Efficiently sampling mixture models - exploration and comparison of methods
Thanks to Semyeong Oh, Adrian Price-Whelan, Jo Bovy, and Dan Foreman-Mackey, for very valuable comments.
This notebook is available at this location on Github.
We will consider the problem of efficiently inferring the parameters of mixture models. We will touch upon the following topics:
- density modelling with Gaussian mixtures
- first (but incorrect) parameter inference with an ensemble sampler (emcee)
- degeneracies, re-parametrization, and correct parameter sampling with emcee
- mapping the full multimodal solution with nested sampling (PolyChord)
- efficient (but unimodal) sampling with Hamiltonian Monte Carlo (HMC)
- gradients and Hessians with automatic differentiation
- sampling all the latent variables with autodifferientiated HMC
Full disclaimer: this tutorial is by no means the final word on how to sample mixture models! It also contains some personal biases with respect to the presentation and choice of methodology/technology. But it should provide a good starting point for those who are interested in using a mixture model and sampling it with MCMC. Despite the simplicity of the model/data considered here, the lessons are actually very deep and broadly applicable.
Don’t be scared by the amount of code. This notebook is *self-contained* and has a lot of tests. This is intentional, since I didn’t want to pretend one can write a complicated MCMC analysis without performing detailed tests and checks at all stages of the work.
Requirements
Some basic knowledge of Bayes theorem, parameter inference via MCMC, and hierarchical probabilistic models.
If you want to run this notebook, you will need matplotlib, scipy, numpy, autograd, emcee, and Polychord.
Some useful references
- Introduction to finite mixture models
- Extreme deconvolution, an alternative to sampling mixture models
- M. Betancourt’s simplex-hypercube mapping
- Introduction to HMC
- Continuously tempered HMC method
- The Matrix Cookbook
- emcee sampler
- Polychord paper
- Stochastic Gradient HMC
%matplotlib inline
%config IPython.matplotlib.backend = 'retina'
%config InlineBackend.figure_format = 'retina'
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import rc
from cycler import cycler
import itertools
import emcee
import corner
import autograd.numpy as np
from autograd.scipy.misc import logsumexp
from autograd import grad, hessian
import numpy as onp
from scipy.optimize import minimize
from scipy.misc import derivative
rc("font", family="serif", size=14)
rc("text", usetex=True)
matplotlib.rcParams['lines.linewidth'] = 2
matplotlib.rcParams['patch.linewidth'] = 2
matplotlib.rcParams['axes.prop_cycle'] =\
cycler("color", ['k', 'c', 'm', 'y'])
matplotlib.rcParams['axes.labelsize'] = 16
What are mixture models?
In the realm of probabilistic models, mixture models are very common. They refer to describing a probability distribution as a linear sum of components
\[p(x) = \sum_i \alpha_i K_i(x)\]The kernels \(\{ K_i(x) \}\) usually belong to some family of probability distributions (e.g., Gaussians). One is usually interested in inferring the amplitude coefficients as well as the parameters of the kernels (e.g., their positions and sizes). Note that to obtain a valid probability distribution function (PDF), both the kernels and the amplitudes must be normalized, e.g., sum to one:
\[\int K_i(x)\mathrm{d}x = 1 \quad \sum_i \alpha_i = 1\]The kernels do not have to be identical or even belong to the same family. Also note that the mixture could be infinite. Both of those extensions are the state of the art of modern statistical modeling, but are advanced topics which will not be covered here.
You might have already realized that this loose definition gives a lot of flexibility. As we will see, this creates numerous technical issues, notably in how mixture models are optimized or sampled when fitting data. In particular, there is the infamous label degeneracy, which refers to the ability to swap components/kernels and leave the total PDF invariant. There is also the mode collapse phenomenon, describing how using too many components might make them describe the data points separately (one component per datum). More generally, the presence components with low amplitudes, infinitely low or high widths, creates various new degeneracies in the posterior distribution. For instance, one can probably add many of those components without changing the quality of the fit to a data set. This is related to model selection, and choosing the number of mixtures. All of those issues are problematic if one attempts to naively sample the mixture parameters with MCMC. Luckily, there are standard tricks to get around them, as we will illustrate below.
One of the main restrictions of this notebook is to focus on one-dimensional mixtures. However, if \(x\) were multidimensional, most of the discussion below would be unchanged - but many of the calculations and illustrations would be much more difficult.
Density modeling with Gaussian Mixtures
We will consider a set of \(N\) points \(\{x_i ; i=1,\cdots,N\}\) generated from the mixture of \(B\) Gaussians, with amplitudes, means, and standard deviations denoted by \(\vec{\alpha},\vec{\beta}, \vec{\gamma}\). Thus, each \(x_i\) is drawn from
\[p(x_i\vert \vec{\alpha},\vec{\beta}, \vec{\gamma}) = \sum_{b=1}^B \alpha_b \mathcal{N}(x_i\vert \beta_b,\gamma^2_b)\]We use the notation \(\mathcal{N}(x\vert \mu,\sigma^2) = (\sqrt{2\pi}\sigma)^{-1} \exp\left(-\frac{1}{2}\left(\frac{x-\mu}{\sigma}\right)^2\right)\)
For each \(x_i\), we observe a noisy version \(y_i\), with Gaussian noise of standard deviation \(\sigma_i\), such that
\[p(y_i\vert x_i, \sigma_i) = \mathcal{N}(y_i\vert x_i,\sigma^2_i)\]which is our likelihood function for each data point.
The variables \(\alpha_b\) are such that \(0 \leq \alpha_b \leq 1\) and \(\sum_{b=1}^B \alpha_b = 1\), i.e., they live on the \(B\)-dimensional simplex.
Let us start by making a simulated data set.
# Those two functions establish a mapping between the B-dimensional simplex
# and the (B-1)-dimensional unit hypercube. This will be described later on.
def zs_to_alphas(zs):
"""Project the hypercube coefficients onto the simplex"""
fac = np.concatenate((1 - zs, np.array([1])))
zsb = np.concatenate((np.array([1]), zs))
fs = np.cumprod(zsb) * fac
return fs
def alphas_to_zs(alphas):
"""Project the simplex coefficients onto the hypercube"""
def fun(z):
return np.sum((zs_to_alphas(z) - alphas)**2.)
res = minimize(fun, x0=np.repeat(0.5, alphas.size-1))
return res.x
nobj = 300
zs = np.array([0.3])
n_mixture = zs.size + 1 # the number of mixtures, i.e. B in the text
alphas = zs_to_alphas(zs)
betas = np.array([0.4, 0.6])
betas.sort() # sorts them
gammas = np.array([0.05, 0.05]) # fixed to some small values
typecounts = np.random.multinomial(nobj, alphas)
types = np.concatenate([np.repeat(i, ni)
for i, ni in enumerate(typecounts)]).astype(int)
xis = betas[types] + gammas[types] * np.random.randn(nobj) # Gaussian draws
xis = np.array([betas[t] + gammas[t] * np.random.randn() for t in types]) # Gaussian
sigmais = np.random.uniform(0.01, 0.15, size=nobj)
yis = xis + sigmais * np.random.randn(nobj) # Gaussian draws from N(x_i, sigma_i)
x_grid = np.linspace(0, 1, 100)
p_x_grid = alphas[None, :] *\
np.exp(-0.5*((x_grid[:, None] - betas[None, :])/gammas[None, :])**2)/\
np.sqrt(2*np.pi)/gammas[None, :]
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
axs[0].hist(xis, histtype='step', normed=True,
label=r'Noiseless samples $$x_i$$')
axs[0].hist(yis, histtype='step', normed=True,
label=r'Noisy samples $$y_i$$')
for t in range(n_mixture):
axs[0].plot(x_grid, p_x_grid[:, t])
axs[0].legend(frameon=True).get_frame().set_linewidth(0)
axs[0].set_xlim([0, 1])
axs[0].set_ylim([0, axs[0].get_ylim()[1]*1.7])
axs[0].set_ylabel(r'$$p(x\vert \vec{\alpha}, \vec{\beta}, \vec{\gamma})$$')
axs[0].set_xlabel(r'$$x$$')
axs[1].errorbar(yis/sigmais, xis-yis, sigmais, fmt="o", lw=1,
markersize=2, ecolor='#888888', alpha=0.75)
axs[1].set_xlabel(r'SNR$$=y_i/\sigma_i$$')
axs[1].set_ylabel(r'$$x_i-y_i$$')
fig.tight_layout()
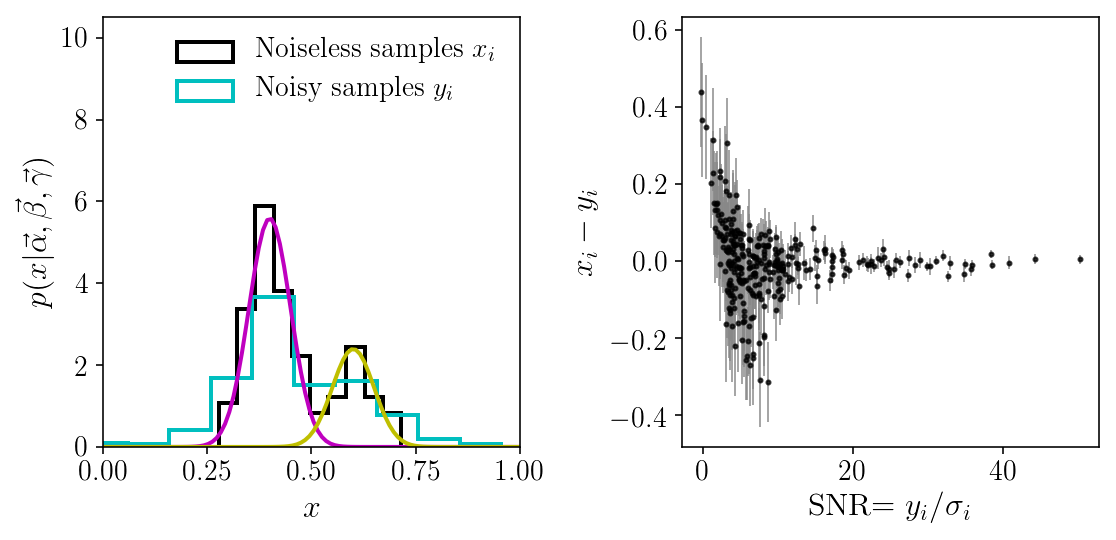
As we can see, our noisy samples span a wider domain than the initial density. Because of the noise, the density is blurried, and we cannot resolve the two components. In fact, we barely guess that there are two components. But, as we will see below, because the noise is known, it can be deconvolved, and we can recover the two components pretty well. Note that this statement is only correct under the assumption of our two-component Gaussian Mixture model! We will see that things are not so simple once this assumption is relaxed and we consider a broader model space.
The posterior distribution(s)
Let us now write the posterior distribution of the parameters of this model. We are interested in recovering \(\vec{\alpha},\vec{\beta}, \vec{\gamma}\) from the noisy data and their errors, \(\{y_i, \sigma_i\}\). Unfortunately, the noiseless values \(\{ x_i \}\) are not observed; they must be modeled and marginalized over. By applying Bayes’ theorem twice and introducing latent \(x_i\)’s, we can write the posterior distribution of interest:
\[p(\vec{\alpha},\vec{\beta}, \vec{\gamma} \vert \{y_i, \sigma_i\}) \propto p(\vec{\alpha},\vec{\beta}, \vec{\gamma}) \prod_{i=1}^N \int \mathrm{d}x_i p(y_i\vert x_i, \sigma_i)p(x_i\vert \vec{\alpha},\vec{\beta}, \vec{\gamma})\]We have dropped the evidence at the denominator, since it is a normalization constant. It would be important if we were comparing models or fitting parameters accross models. For parameter estimation within one model (here with two components), it is unimportant.
By making the distributions explicit, our full posterior distribution reads
\[p(\vec{f},\vec{\beta}, \vec{\gamma} \vert \{y_i, \sigma_i\})\propto p(\vec{f},\vec{\beta}, \vec{\gamma}) \prod_{i=1}^N \sum_{b=1}^B f_b \int \mathrm{d}x_i\mathcal{N}(x_i\vert \beta_b,\gamma^2_b)\mathcal{N}(y_i\vert x_i,\sigma^2_i)\]However, notice that we are in a very special context: both our distribution model and our likelihood are Gaussian. In other words, the expression for the posterior probability contains an integral over a product of two Gaussians. This can be resolved analytically, and leads to
\[p(\vec{\alpha},\vec{\beta}, \vec{\gamma} \vert \{y_i, \sigma_i\}) \propto p(\vec{\alpha},\vec{\beta}, \vec{\gamma}) \prod_{i=1}^N \sum_{b=1}^B \alpha_b \mathcal{N}(y_i\vert \beta_b,\sigma^2_i + \gamma^2_b)\]If you are note sure how to do that, please look at the Matrix Cookbook! The reference is above.
This is a very convenient result since we have once and for all removed the latent variables and integrals, and we obtained a simple expression for the posterior distribution of interest. We will refer to this expression as the “simplified” posterior, while the previous one, with the set of latent variables and integrals, is the “full” posterior. Because this analytical elimination of the latent variables is not always possible, and because sometimes one does want to explicitly sample them, the full posterior is of great interest. Below we will see to correctly sample it and deal with the large number of parameters.
Why would we want to explore the full set of parameters, especially if we are able to eliminate a large number of them? This is because we might be interested in recovering the true noiseless values \(x_i\)’s. More precisely, we may want to look at the join posterior distribution on the \(x_i\)’s and the mixture model. We may find that some values are well recovered regardless of the mixture, while some other might not. More generally, this is because of a shrinkage property of Bayesian hierarchical models: by simulatenously recovering the population parameters \(\vec{\alpha},\vec{\beta}, \vec{\gamma}\) and the object parameters \(x_i\)’s, we will obtain stronger constraints on \(x_i\) than by using the objects individually (i.e., the likelihood function \(p(y_i\vert x_i, \sigma_i)\)). This is a natural yet powerful consequence of the hierarchical nature of the model and the parameter inference, which we cannot quite access if we analytically marginalize over the latent variables. We will illustrate this shrinkage property below.
Minor comment: we have integrated each \(x_i\) in \([-\infty, \infty]\), but we will adopt bounded priors \([0,1]\) in the other numerical tests below. This difference does not affect our investigations. If we wanted to be very precise, we could easily include truncated gaussians in the simplified posterior distribution.
We will try sampling both of those posterior distributions below. This is because in many real-world problems this analytic simplification is not possible, and one has to work with the full posterior distribution, which might involve many latent variables and integrals. This would be the case if our population model and/or our noise were not Gaussian. We will work with this toy model because we have the simplified posterior distribution to verify our results.
# Let's first define a few basic functions we will need.
def alphaszs_jacobian(fs, zs):
"""Jacobian of the simplex-to-hypercube transformation"""
jaco = np.zeros((zs.size, fs.size))
for j in range(fs.size):
for i in range(zs.size):
if i < j:
jaco[i, j] = fs[j] / zs[i]
if i == j:
jaco[i, j] = fs[j] / (zs[j] - 1)
return jaco
def lngaussian(x, mu, sig):
"""Just the log of a normalized Gaussian"""
return - 0.5*((x - mu)/sig)**2 - 0.5*np.log(2*np.pi) - np.log(sig)
def gaussian(x, mu, sig):
"""Just a normalized Gaussian"""
return np.exp(lngaussian(x, mu, sig))
# Let's also define a convenient function for testing gradients and derivatives.
# We compare the analytic prediction to the numerical derivative.
def test_derivative(x0, fun, fun_grad, relative_accuracy, n=1, lim=0, order=9, dxfac=0.01,
verbose=False, superverbose=False):
grads = fun_grad(x0)
for i in range(x0.size):
if verbose:
print(i, end=" ")
def f(v):
x = 1*x0
x[i] = v
return fun(x)
grads2 = derivative(f, x0[i], dx=dxfac*x0[i], order=order, n=n)
if superverbose:
print(i, grads2, grads[i])
if np.abs(grads2) >= lim:
onp.testing.assert_allclose(grads2, grads[i],
rtol=relative_accuracy)
First MCMC : raw model
Let us sample the simplified posterior distribution (which, for our fake data set, has 6 parameters: the amplitudes, means, and standard deviations of the two Gaussian components) with a very good sampler: emcee. The reasons why emcee is a good sampler are beyond the scope of this tutorial (but scale invariance and speed are two of them!). As mentioned before, we adopt uniform priors in \([0,1]\) for all parameters. We will manually impose \(\sum_b \alpha_b = 1\) by renormalizing them systematically at each random draw.
# The simplified posterior distribution is easy to code up:
def lnprob_hyperonly1(params):
alphas = params[0:n_mixture]
betas = params[n_mixture:2*n_mixture]
gammas = params[2*n_mixture:3*n_mixture]
alphas /= np.sum(alphas) # to enforce the normalization
likes = np.log(alphas[None, :]) +\
lngaussian(yis[:, None], betas[None, :],
np.sqrt(gammas[None, :]**2. + sigmais[:, None]**2.))
return - np.sum(logsumexp(likes, axis=1))
def lnprob(params): # log posterior distribution to be given to emcee
alphas = params[0:n_mixture]
betas = params[n_mixture:2*n_mixture]
gammas = params[2*n_mixture:3*n_mixture]
# some reasonnable parameter bounds
if np.any(params <= 0.0) or np.any(params >= 1.0):
return -np.inf
return - lnprob_hyperonly1(params)
params = np.concatenate([alphas, betas, gammas])
ndim = params.size
nwalkers = ndim * 30
# initial set of walkers
p0s = []
for i in range(nwalkers):
lnp = -np.inf
while ~np.isfinite(lnp):
p0 = np.random.uniform(0.03, 0.97, ndim)
p0[0:n_mixture] /= np.sum(p0[0:n_mixture])
lnp = lnprob(p0)
p0s += [p0]
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob, threads=4)
pos, prob, state = sampler.run_mcmc(p0s, 1000)
sampler.reset()
_ = sampler.run_mcmc(pos, 1000)
param_names = [r'$$\alpha_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]
_ = corner.corner(sampler.flatchain, truths=params, labels=param_names)
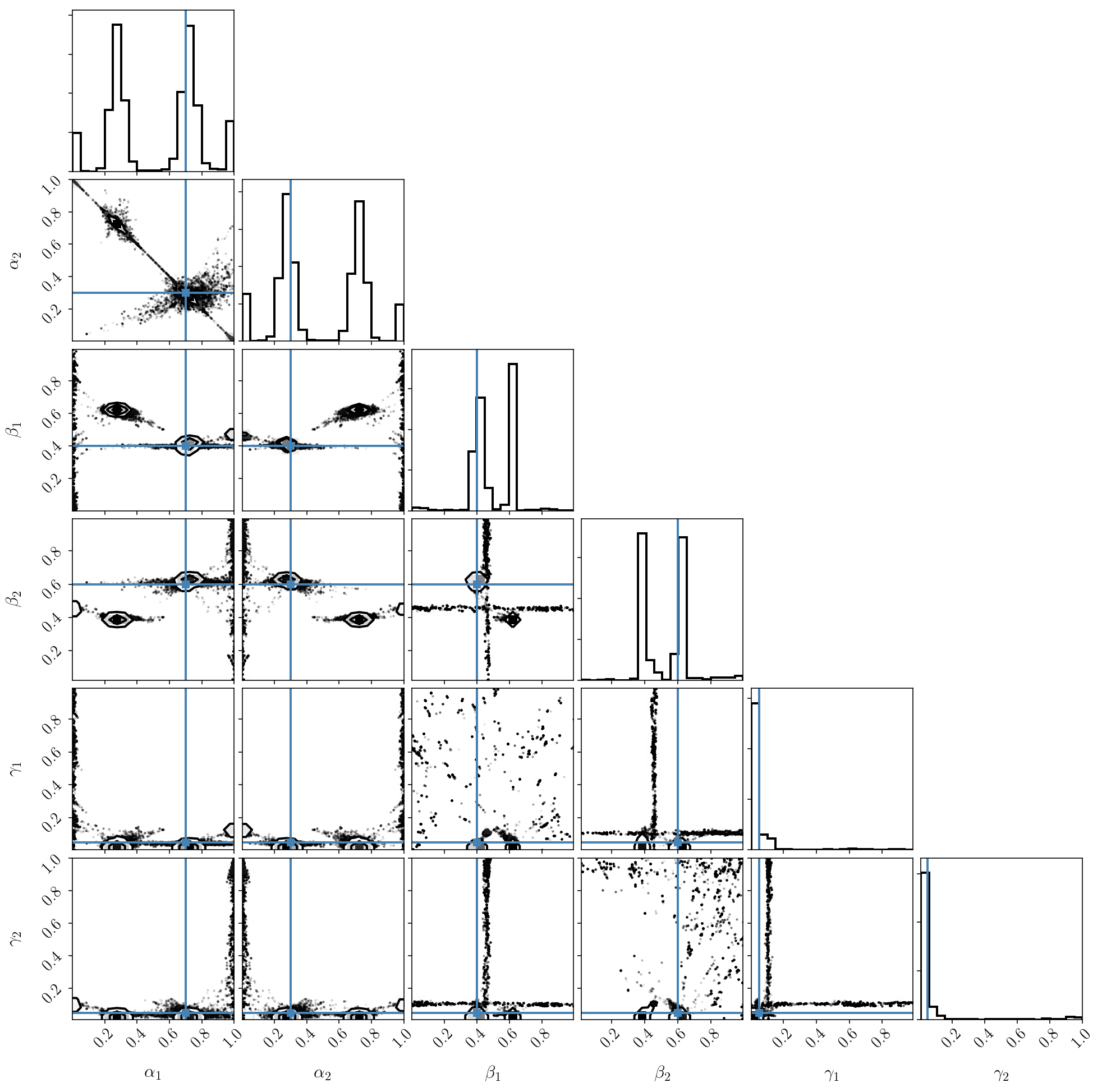
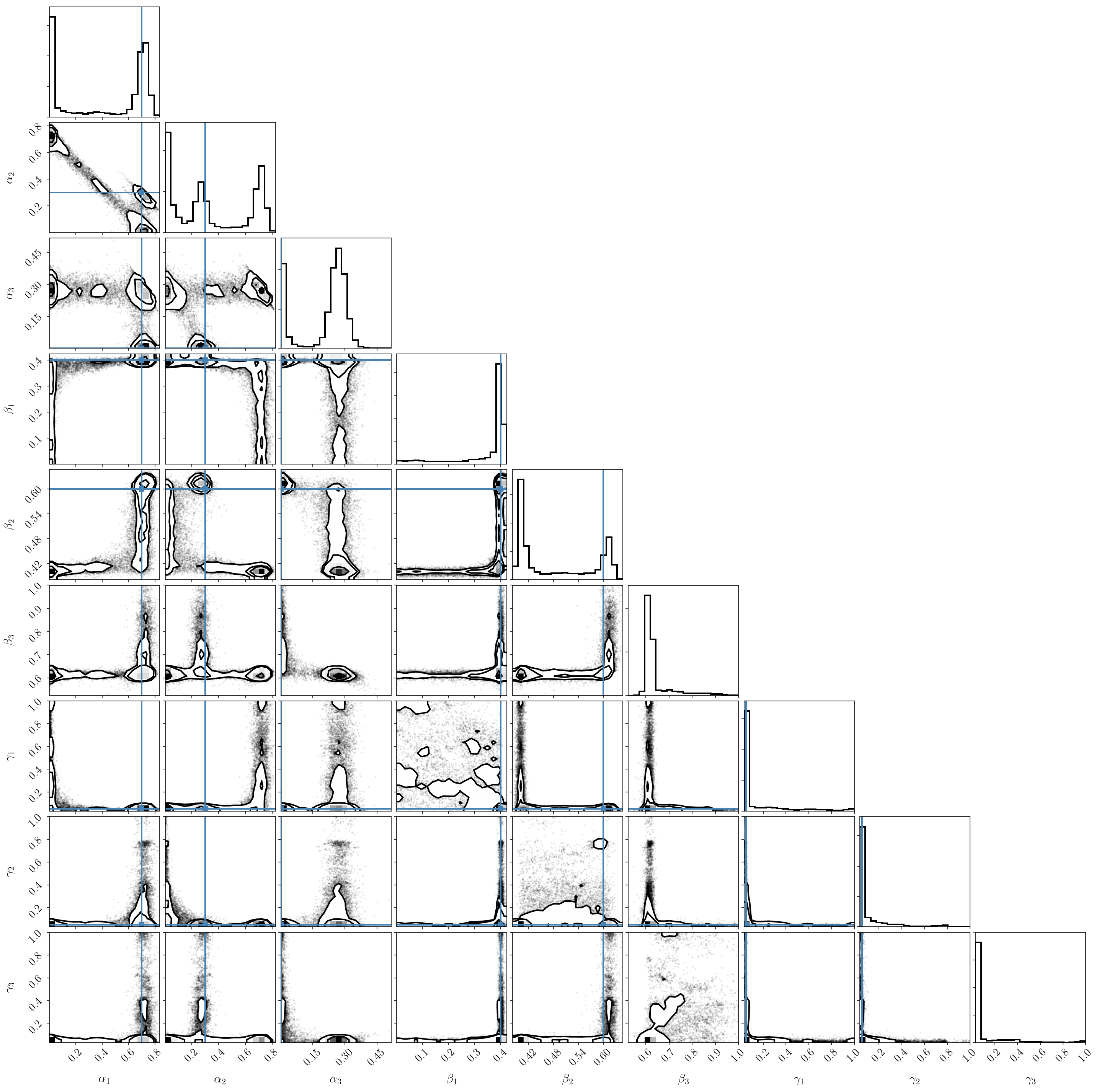
As we can see, the result is surprisingly nasty! In fact, running MCMC on this distribution is incorrect. The posterior distribution has strong degeneracies and is multimodal, so standard MCMC will not work. As an exercise, you can check that the sampler has not converged. Also, even if it looks like it is finding multiple modes, you can also check that the density of samples is incorrect at those locations, and is not proportional to the posterior distribution.
We briefly mentioned this phenomenon before. The degeneracy between \(\alpha\)’s is due to them being normalized and constrained to sum to one. As a result, the posterior distribution, by construction, lives on a thin slice in \(\alpha\) space.
There are a few ways one could solve this problem. I like that introduced by M. Betancourt (arxiv:1010.3436) since it is simple to implement and it leads to simple derivatives. It establishes a bijective mapping between the \((B-1)-\) hypercube and the \(B-\)simplex, by constructing coefficients \(z_i\)’s with \(0\leq z_i \leq 1\) for \(i=1, \cdots, B-1\), and no normalization condition. In simpler terms, this means that we can use the \(z_i\) coefficients (\(B-1\) of them, in \([0,1\)]) instead of the \(\alpha_b\) coefficients (\(B\) of them, on the simplex), which is very convenient. For each draw of \(z_i\)’s in the hypercube, the simplex coefficients (the amplitudes of our mixture components) are found with
\[\alpha_b = \prod_{i=1}^{b-1} z_i \cdot \left\{\begin{array}{ll}1-z_b &\mathrm{if\ }b < B \\ 1 &\mathrm{if\ } b = B \end{array}\right.\]There are other possibilities for mapping the simplex onto closes volumes, but not all of them lead to simple derivatives (via a change of variable), which is often critical for some inference methods, like the HMC we will use later on.
Moreover, there is an additional complication that made our sampling failed: the labeling degeneracy. That is, we haven’t imposed a specific order to the components, which means they can be swapped and lead to the same value of the posterior distribution. This degeneracy is well known and leads to a perfectly multimodal distribution (with \(B!\) modes!). Since the mapping between those modes is known, a simple solution is to tune the prior and only explore one of them. In one dimension, this can be achieved by enforcing the order of the components (for example their \(\beta\)’s) in the prior itself. Note that in multidimentional cases, this condition is more difficult to enforce.
Second MCMC run: emcee with reparametrized model
We will now order the component locations and use the hypercube-to-simplex mapping to run the emcee sampler once again. We will also make some tighted assumptions about the component amplitudes and widths. We don’t want those to be too small in order to avoid new sources of degeneracies in the posterior distribution, like the mode collapse. (This point will be illustrated in the next section).
def lnprob(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
if np.any(zs < 0.1) or np.any(zs > 0.8):
return -np.inf
alphas = zs_to_alphas(zs)
for i in range(n_mixture-1): # We enforce an order to the components
if betas[i] >= betas[i+1]:
return -np.inf
if np.any(params <= 0.0) or np.any(params >= 0.9):
return -np.inf
return - lnprob_hyperonly1(np.concatenate((alphas, params[n_mixture-1:])))
params = np.concatenate([zs, betas, gammas])
ndim = params.size
nwalkers = ndim * 30
p0s = []
for i in range(nwalkers):
lnp = -np.inf
while ~np.isfinite(lnp):
p0 = np.random.uniform(0.03, 0.9, ndim)
p0[n_mixture-1:2*n_mixture-1].sort()
lnp = lnprob(p0)
p0s += [p0]
sampler = emcee.EnsembleSampler(nwalkers, ndim, lnprob, threads=4)
pos, prob, state = sampler.run_mcmc(p0s, 1000)
sampler.reset()
new_pos = emcee.utils.sample_ball(np.median(pos, axis=0),
np.full(pos.shape[1], 1e-5),
size=nwalkers)
pos,_,_ = sampler.run_mcmc(new_pos, 1000)
sampler.reset()
pos,_,_ = sampler.run_mcmc(pos, 1000)
param_names = [r'$$z_'+str(i+1)+'$$' for i in range(n_mixture-1)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]
_ = corner.corner(sampler.flatchain, truths=params, labels=param_names)
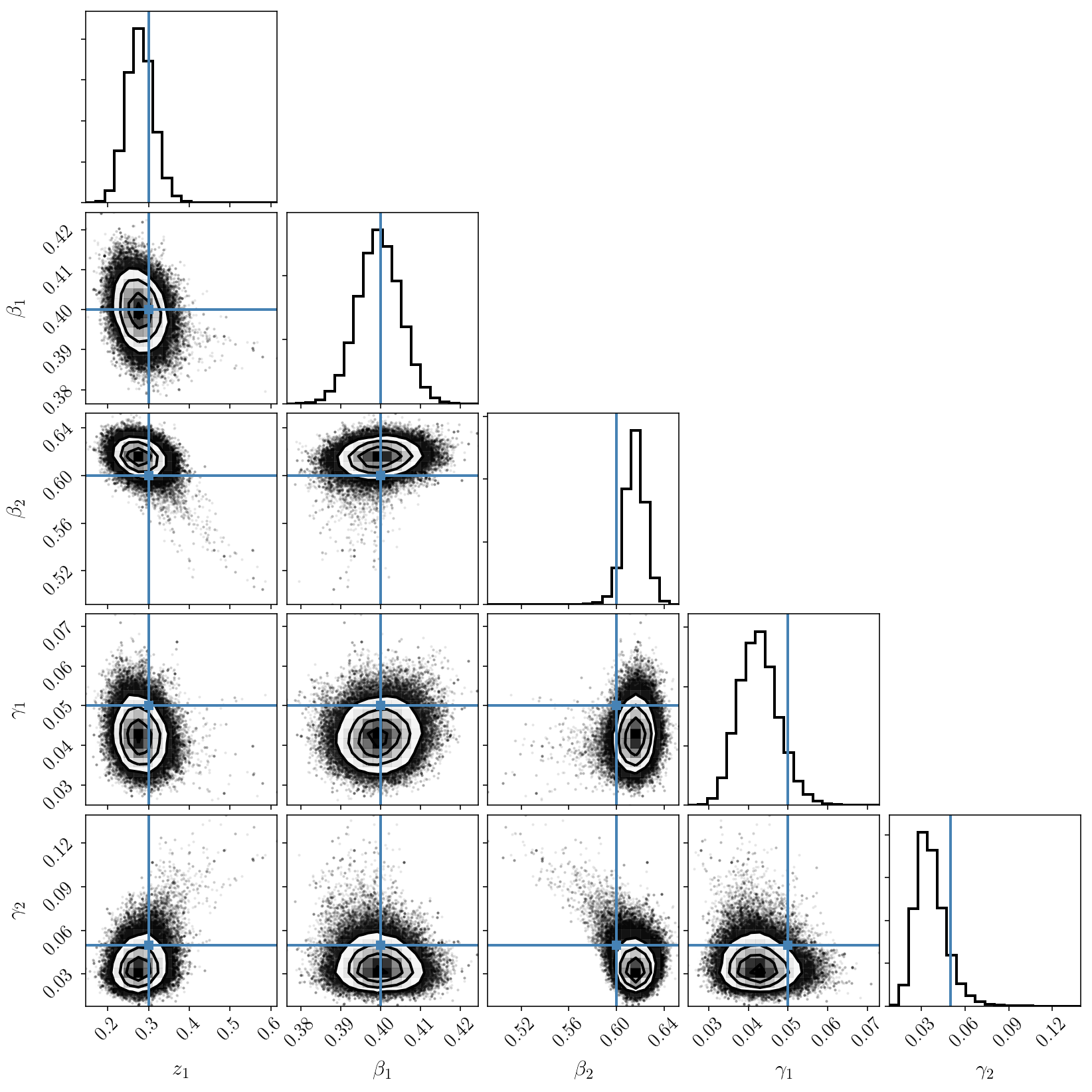
We now see that we have solved those issues and that we obtain a nicely sampled unimodal posterior distribution, with the true values correctly included.
(If you still see some strange tail and isolated samples that seem to indicate a secondary mode, please ignore this at the moment. This is real, and will be discussed later on.)
Note that our sampling procedure is very quick: the two runs merely took a few seconds. This is because emcee has many nice properties and is parallelized. Yet, as we will discuss below, more efficient approaches exist (in terms of the fraction of random proposed samples that are accepted), and those are essential for scaling up from a few parameters to… many millions!
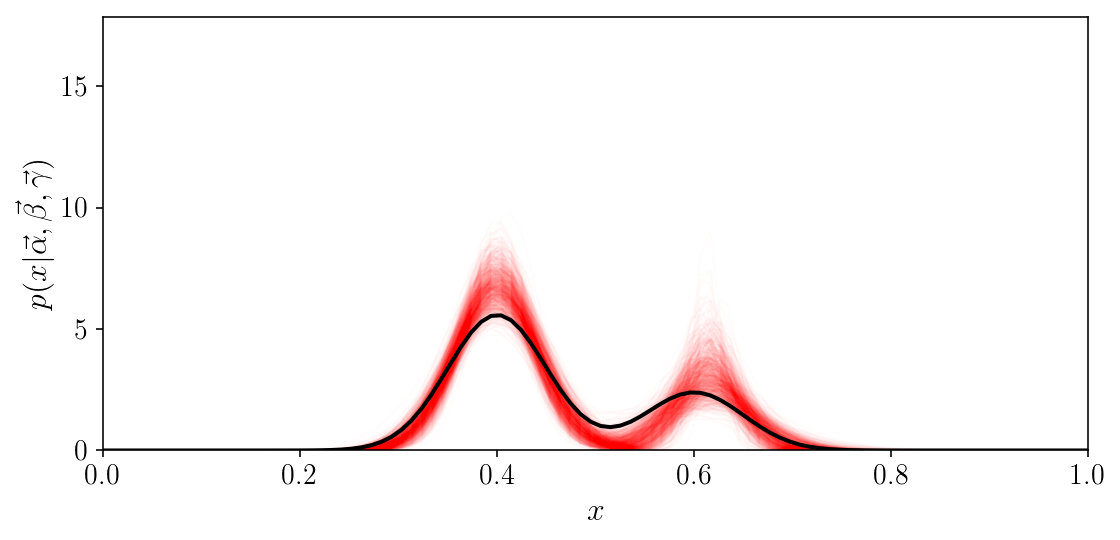
A nice visualization of the result is in data space, where we evaluate our model for a few hundred samples of the posterior distribution, and see that they are nicely around the truth.
fig, ax = plt.subplots(1, 1, figsize=(8, 4))
for i in np.random.choice(sampler.flatchain.shape[0], 1000, replace=False):
alphas2 = zs_to_alphas(sampler.flatchain[i, 0:n_mixture-1])
betas2 = sampler.flatchain[i, n_mixture-1:2*n_mixture-1]
gammas2 = sampler.flatchain[i, 2*n_mixture-1:3*n_mixture-1]
p_x_grid2 = alphas2[None, :] *\
np.exp(-0.5*((x_grid[:, None] - betas2[None, :])/gammas2[None, :])**2)/\
np.sqrt(2*np.pi)/gammas2[None, :]
p_x_grid2 = np.sum(p_x_grid2, axis=1)
ax.plot(x_grid, p_x_grid2, color='r', alpha=0.01, lw=1)
ax.plot(x_grid, p_x_grid[:, :].sum(axis=1), c='k')
ax.set_xlim([0, 1])
ax.set_ylim([0, axs[0].get_ylim()[1]*1.7])
ax.set_ylabel(r'$$p(x\vert \vec{\alpha}, \vec{\beta}, \vec{\gamma})$$')
ax.set_xlabel(r'$$x$$')
fig.tight_layout()
Visualizing the labelling degeneracy with PolyChord
Let us now investigate and try to understand the structure of our simplified posterior distribution. We will use the simplex-to-hypercube mapping, but no longer order the components.
Standard MCMC techniques like Metropolis-Hasting or Ensemble approaches, in their standard implementations, will only correctly sample uni-modal distributions. Some of them can be extended to deal with multimodality. Yet, the most widespead solution for fully mapping a multimodal distribution is nested sampling. PolyChord is one of the most sophisticated implementations of this sampling scheme, and is able to accurately map very complicated distributions.
There is a cost: nested sampling typically requires many more function evaluations than standard MCMC, and also has a few parameters that need to be tuned. We will not cover that last point here, but you should know that running nested sampling may require some tuning via trial and error. Finally, we won’t discuss or make use of the fact that nested sampling delivers the model evidence (or marginalized likelihood), which is essential for performing model comparison.
Let us run PolyChord on our data set, with the same posterior, no ordering constraints, and two components only.
# Save the data to numpy arrays since we will run polychord outside of this notebook.
np.save("yis", yis)
np.save("sigmais", sigmais)
# The code we will write to a file and execute to run PolyChord.
# the only parameter of this string is the number of components.
# the second string has a parameter for (de)activating the clustering algorith.
code1 = """
import numpy as np
import sys
sys.path.append('/Users/bl/Dropbox/software/PolyChord') # Put correct path here.
import PyPolyChord.PyPolyChord_wrapper as PolyChord
n_mixture = %i
ndim = 3*n_mixture - 1
nderived = 0
yis = np.load("yis.npy")
sigmais = np.load("sigmais.npy")
def prior(cube):
theta = [0.0] * ndim
for i in range(n_mixture):
theta[i] = cube[i]
theta[n_mixture-1+i] = cube[n_mixture-1+i]
theta[2*n_mixture-1+i] = 0.03 + 0.97 * cube[2*n_mixture-1+i]
return theta
def mixturemodellnprob(params):
phi = [0.0] * 0
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
fac = np.array([1.0]*n_mixture)
zsb = np.array([1.0]*n_mixture)
for i in range(n_mixture-1):
fac[i] = 1. - zs[i]
zsb[i+1] = zs[i]
alphas = np.cumprod(zsb) * fac
like = 0.*yis
for i in range(n_mixture):
sig = np.sqrt(gammas[i]**2. + sigmais[:]**2.)
like += alphas[i] * np.exp(-0.5*((yis[:]-betas[i])/sig)**2.) / sig
logL = np.sum(np.log(like))
return logL, phi
"""
code2 = """
PolyChord.run_nested_sampling(mixturemodellnprob, ndim, nderived, prior=prior,
file_root='mixturemodellnprob', do_clustering=%s,
nlive=100*ndim, update_files=100*ndim,
num_repeats=10*ndim, boost_posterior=5)
"""
text_file = open("run_PyPolyChord.py", "w")
text_file.write(code1 % 2 + code2 % True)
text_file.close()
# go in the terminal and run
# rm -rf chains ; mkdir chains ; mkdir chains/clusters ; python run_PyPolyChord.py
# If you get a segmentation fault, you'll need to compile PolyChord with extra flags
# to make sure the stack size is sufficient.
Let’s visualize the posterior distribution. In this figure we will also plot all the ordering permutations of our true parameter values.
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
param_names = [r'$$z_'+str(i+1)+'$$' for i in range(n_mixture-1)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]
fig = corner.corner(samples[:, 2:], ranges=[[0, 1]*(3*n_mixture-1)], labels=param_names)
#samples = np.genfromtxt('chains/mixturemodellnprob_phys_live.txt')
#fig = corner.corner(samples[:, :-1])
# If you want to plot the live points while PolyChord runs.
axs = np.array(fig.axes).reshape((3*n_mixture - 1, 3*n_mixture - 1))
for ind in itertools.permutations(range(n_mixture)):
order = np.array(ind)
truths = np.concatenate((alphas_to_zs(alphas[order]), betas[order], gammas[order]))
for i in range(3*n_mixture - 1):
axs[i, i].axvline(truths[i], c="#4682b4")
for j in range(i):
axs[i, j].axhline(truths[i], c="#4682b4")
axs[i, j].axvline(truths[j], c="#4682b4")
axs[i, j].plot(truths[j], truths[i], "s", color="#4682b4")
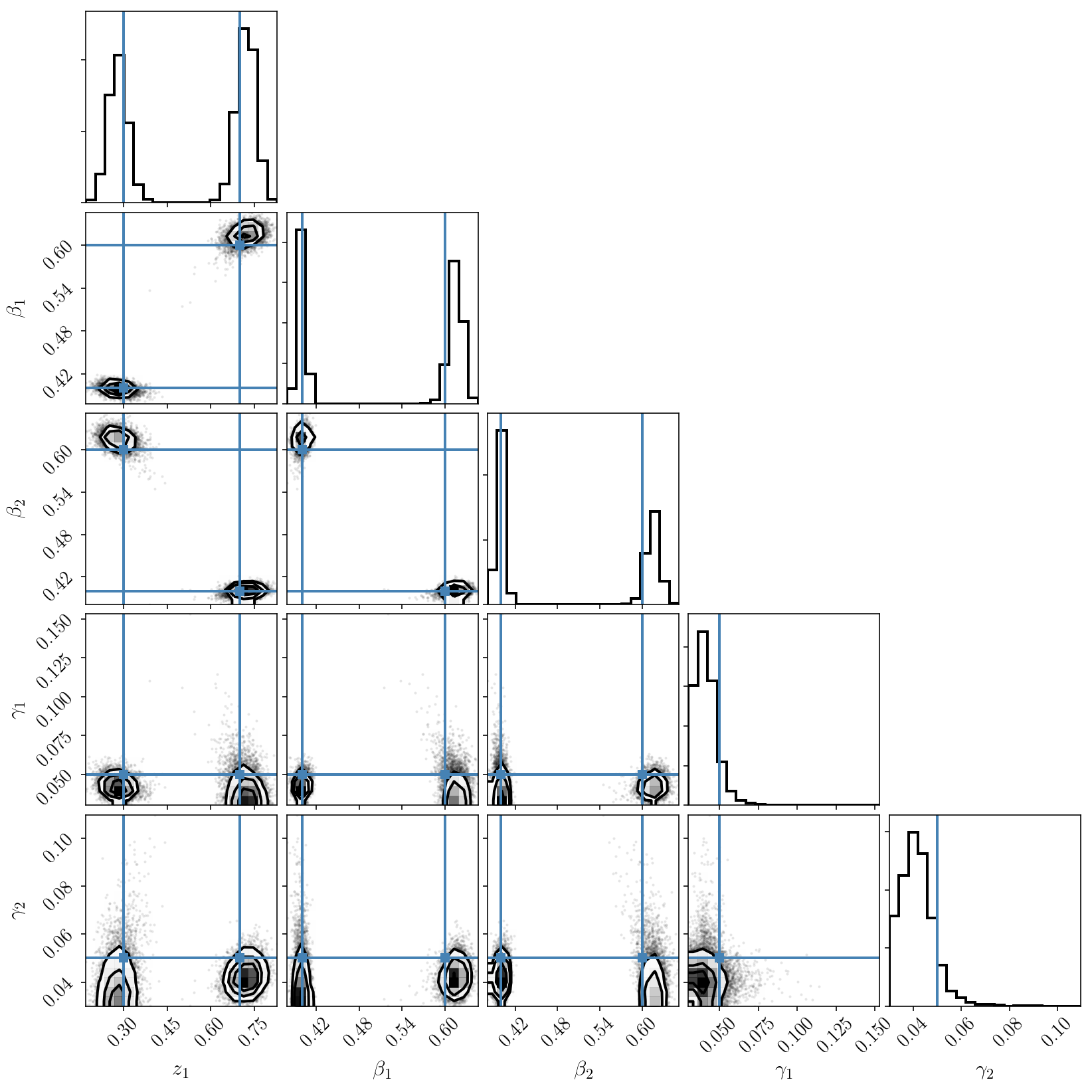
We can now see the two modes caused by the labelling degeneracy! PolyChord nicely finds and map them. Since we have activated the clustering algorithm, we can restrict our attention to one of the modes and plot posterior samples. Indeed, we check that our inference is correct.
samples = np.genfromtxt('chains/clusters/mixturemodellnprob_1_equal_weights.txt')
mus = np.mean(samples[:, 2:], axis=0)
sigs = np.std(samples[:, 2:], axis=0)
ranges = [[mu-3.5*sig, mu+2.5*sig] for mu, sig in zip(mus, sigs)]
param_names = [r'$$z_'+str(i+1)+'$$' for i in range(n_mixture-1)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]
fig = corner.corner(samples[:, 2:], range=ranges, labls=param_names)
axs = np.array(fig.axes).reshape((3*n_mixture - 1, 3*n_mixture - 1))
for ind in itertools.permutations(range(n_mixture)):
order = np.array(ind)
truths = np.concatenate((alphas_to_zs(alphas[order]), betas[order], gammas[order]))
for i in range(3*n_mixture - 1):
axs[i, i].axvline(truths[i], c="#4682b4")
axs[i, i].set_xlim(ranges[i])
for j in range(i):
axs[i, j].axhline(truths[i], c="#4682b4")
axs[i, j].axvline(truths[j], c="#4682b4")
axs[i, j].plot(truths[j], truths[i], "s", color="#4682b4")
axs[i, j].set_xlim(ranges[j])
axs[i, j].set_ylim(ranges[i])
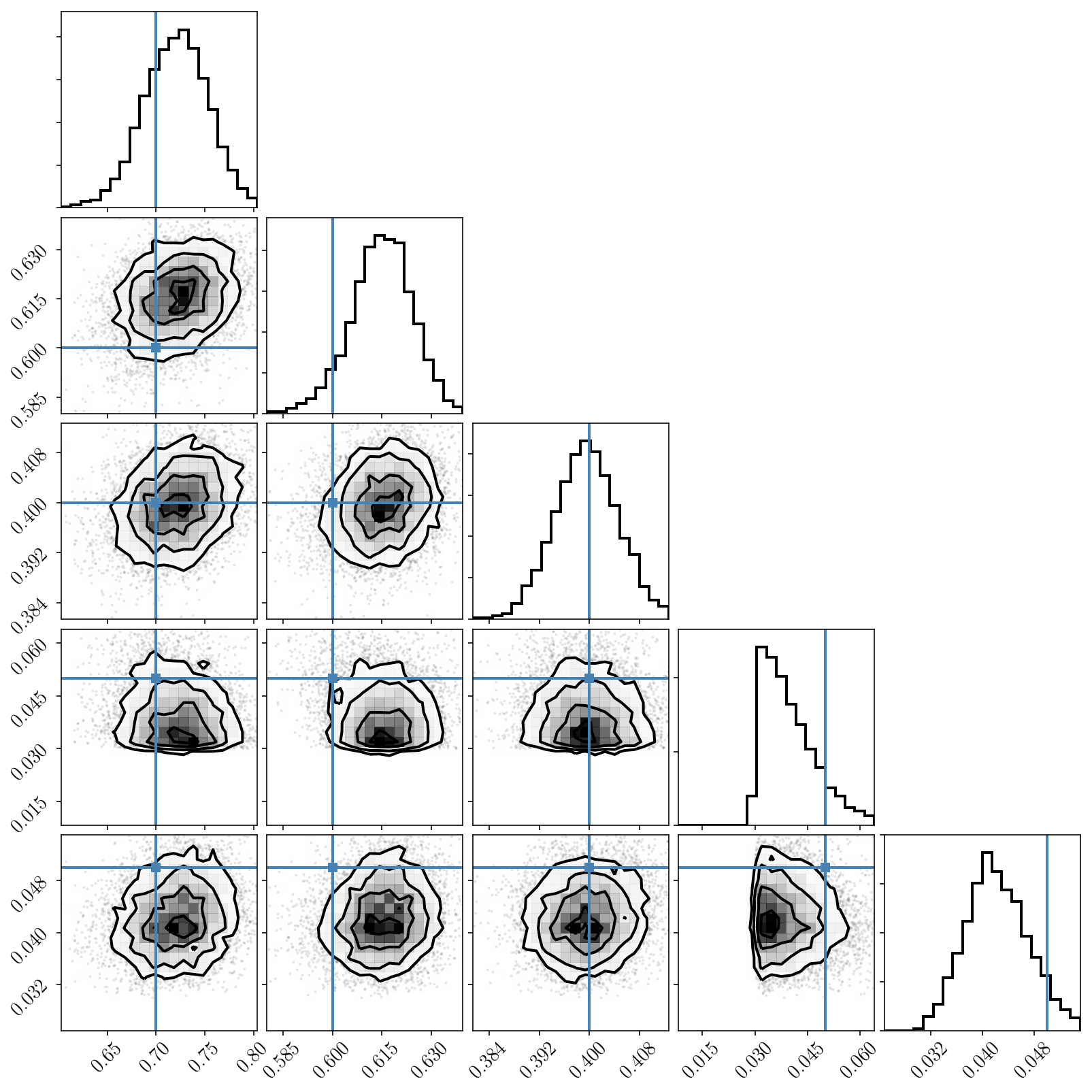
Post-processing the chain
You may wonder, since the mapping between the two modes is predictable, why we don’t simply post-process the chains to order the components and manually merge the modes? This is indeed a very good solution to return to a unimodal case. Unsurprisingly, it is more sampled that the plot we just made with PolyChord’s solution for a single cluster, since we’ve just merged all the clusters by reordering.
Note that this trick must be very carefully applied. One cannot just post-processed any MCMC chain to alleviate the multimodality problem (for mixture models only!). This will only work if the MCMC sampler has converged and properly explored the multiple modes it has mapped (though it is insensitive the the relative amplitudes in this exploration, for obvious geometrical reasons). In our case this is valid.
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
unordered_samples = samples[:, 2:]
ordered_samples = np.zeros((unordered_samples.shape[0],
unordered_samples.shape[1]))
for i in range(unordered_samples.shape[0]):
thealphas = zs_to_alphas(unordered_samples[i, 0:n_mixture-1])
thebetas = unordered_samples[i, n_mixture-1:2*n_mixture-1]
thegammas = unordered_samples[i, 2*n_mixture-1:3*n_mixture-1]
order = np.argsort(thebetas)
ordered_samples[i, 0:n_mixture-1] = alphas_to_zs(thealphas[order])
ordered_samples[i, n_mixture-1:2*n_mixture-1] = thebetas[order]
ordered_samples[i, 2*n_mixture-1:3*n_mixture-1] = thegammas[order]
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
truths = np.concatenate((zs, betas, gammas))
param_names = [r'$$\alpha_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]
fig = corner.corner(ordered_samples, labels=param_names, truths=truths)
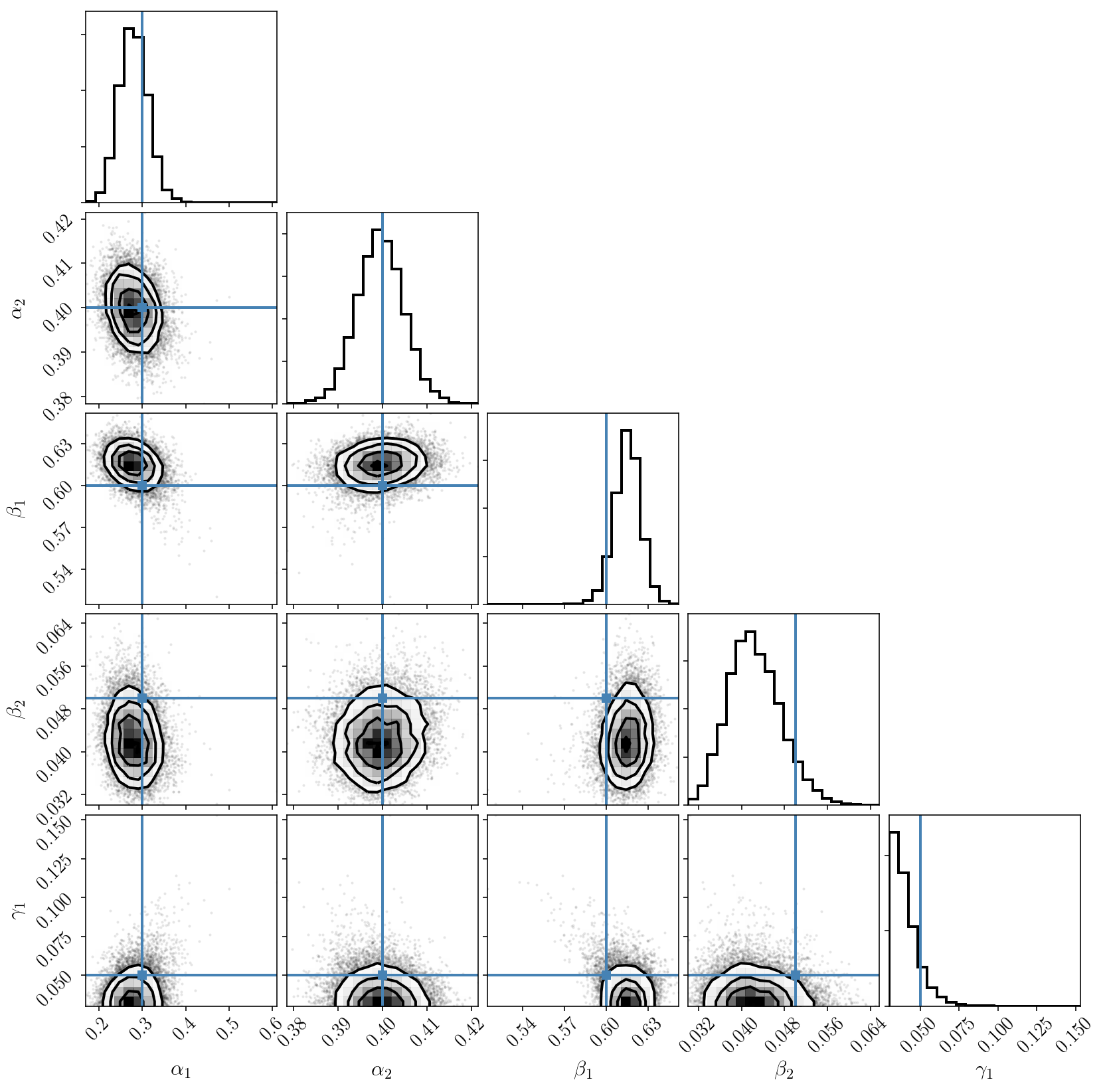
Note that this PolyChord run took a few minutes. This is because nested sampling is generally calls the posterior distribution more times than MCMC, and our calls were not parallelized here. We have also tuned the parameters to sample the posterior distribution in a conservative fashion. One could certainly find better parameters that lead to a more efficient sampling.
More components
Let’s do a more difficult run: perform the inference via PolyChord and three components instead of two. What will we see? Unfortunately, this run will be even slower and take several minutes, but the comments above apply again: this could be made more efficient if necessary.
n_mixture2 = 3
text_file = open("run_PyPolyChord.py", "w")
text_file.write(code1 % n_mixture2 + code2 % False)
# run without clustering to speed it up.
text_file.close()
# go in the terminal and run
# rm -rf chains ; mkdir chains ; mkdir chains/clusters ; python run_PyPolyChord.py
# If you get a segmentation fault, you'll need to compile PolyChord with extra flags
# to make sure the stack size is sufficient.
If we plot the posterior distribution, we immediately see that the labeling degeneracy has gotten worse (since it scales as factorial \(B\)), and that the two-component model is clearly preferred (we nicely recover our input parameters). In other words, one of the components is constrained to be zero.
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
param_names = [r'$$z_'+str(i+1)+'$$' for i in range(n_mixture2-1)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture2)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture2)]
fig = corner.corner(samples[:, 2:], ranges=[[0, 1]*(3*n_mixture2-1)], labels=param_names)
#samples = np.genfromtxt('chains/mixturemodellnprob_phys_live.txt')
#fig = corner.corner(samples[:, :-1])
# If you want to plot the live points while PolyChord runs.
axs = np.array(fig.axes).reshape((3*n_mixture2 - 1, 3*n_mixture2 - 1))
alphas2 = np.concatenate((alphas, np.repeat(0.00, n_mixture2-n_mixture)))
betas2 = np.concatenate((betas, np.repeat(0.00, n_mixture2-n_mixture)))
gammas2 = np.concatenate((gammas, np.repeat(0.00, n_mixture2-n_mixture)))
for ind in itertools.permutations(range(n_mixture2)):
order = np.array(ind)
truths = np.concatenate((alphas_to_zs(alphas2[order]), betas2[order], gammas2[order]))
for i in range(3*n_mixture2 - 1):
axs[i, i].axvline(truths[i], c="#4682b4")
for j in range(i):
axs[i, j].axhline(truths[i], c="#4682b4")
axs[i, j].axvline(truths[j], c="#4682b4")
axs[i, j].plot(truths[j], truths[i], "s", color="#4682b4")
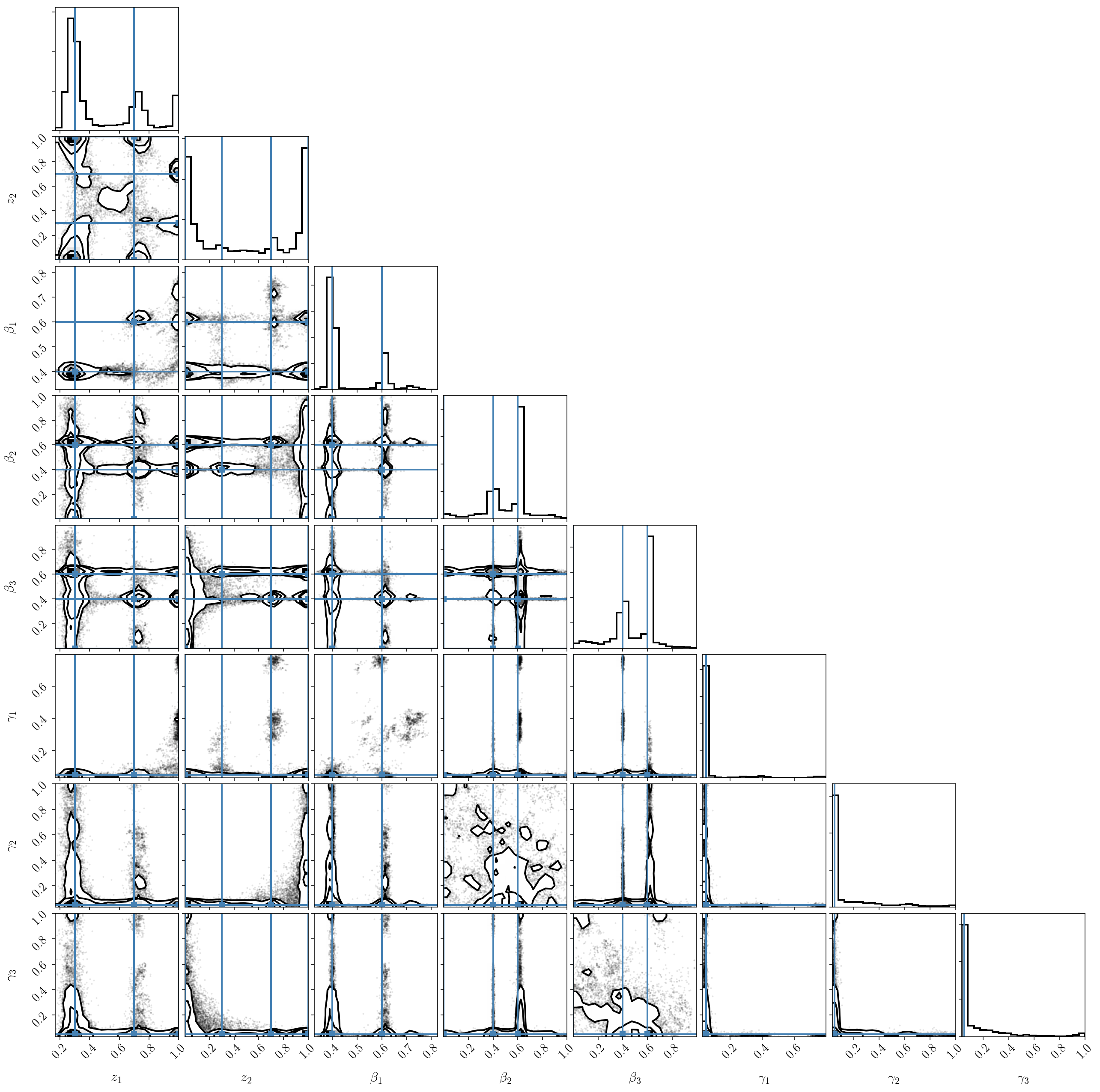
If we try the previous trick and post-process the chains to reorder the components, we see that the result is not satisfactory at all! This is because the parameters of the third (small) component are unconstrained because it doesn’t fit the data. It ends up interfering with the two others.
Unfortunately, we can only conclude that the labeling degeneracy is not that easily killed. We have seen that nested sampling is a natural solution to map out the full posterior distribution. But isn’t there another way to do standard MCMC and map a single of the modes? This is what we will do now with HMC.
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
unordered_samples = samples[:, 2:]
ordered_samples = np.zeros((unordered_samples.shape[0],
unordered_samples.shape[1] + 1))
for i in range(unordered_samples.shape[0]):
thealphas = zs_to_alphas(unordered_samples[i, 0:n_mixture2-1])
thebetas = unordered_samples[i, n_mixture2-1:2*n_mixture2-1]
thegammas = unordered_samples[i, 2*n_mixture2-1:3*n_mixture2-1]
order = np.argsort(thebetas)
ordered_samples[i, 0:n_mixture2] = thealphas[order]
ordered_samples[i, n_mixture2:2*n_mixture2] = thebetas[order]
ordered_samples[i, 2*n_mixture2:3*n_mixture2] = thegammas[order]
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')
alphas2 = np.concatenate((alphas, np.repeat(0.00, n_mixture2-n_mixture)))
betas2 = np.concatenate((betas, np.repeat(0.00, n_mixture2-n_mixture)))
gammas2 = np.concatenate((gammas, np.repeat(0.00, n_mixture2-n_mixture)))
truths = np.concatenate((alphas2, betas2, gammas2))
param_names = [r'$$\alpha_'+str(i+1)+'$$' for i in range(n_mixture2)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture2)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture2)]
fig = corner.corner(ordered_samples, labels=param_names, truths=truths)
HMC with automatic differentiation
On top of our wish to efficiently sample one single mode of the posterior distribution, let’s return to a comment we made at the start: there are few real-world situations where the population and likelihood probabilities are Gaussian and one can integrate over the latent variables analytically. Therefore, we would like to see if we can sample from the full posterior distribution. In other words, we will sample from
\[p(\vec{\alpha},\vec{\beta}, \vec{\gamma}, \{ x_i \} \vert \{y_i, \sigma_i\})\propto p(\vec{\alpha},\vec{\beta}, \vec{\gamma}) \prod_{i=1}^N \sum_{b=1}^B \alpha_b \mathcal{N}(x_i\vert \beta_b,\gamma^2_b)\mathcal{N}(y_i\vert x_i,\sigma^2_i)\]By histogramming the samples only in the \(\vec{\alpha},\vec{\beta}, \vec{\gamma}\) dimensions, we should recover the previous results from the simplified posterior distribution \(p(\vec{\alpha},\vec{\beta}, \vec{\gamma}, \{ x_i \} \vert \{y_i, \sigma_i\})\) since this is equivalent to numerically integrating out the \(x_i\)’s. This is a classic MCMC trick: if one draws samples from a distribution \(p(a,b)\) and only look at the \(a\) dimension (by histogramming the \(a\) values and ignoring \(b\)), one is effectively looking at the marginalized posterior \(p(a) = \int p(a,b) \mathrm{d}b\).
Since this model has many more parameters (\(3B+N-1\) instead of \(3B-1\)), standard MCMC methods like emcee will struggle. This is because those have a typical acceptance rate of \(\approx 0.3\) (at best), which is the cornerstone of standard MCMC algorithms like Metropolis-Hastings. This can only be increased by using extra information such as gradients, which we will do below. Moreover, due to volume effects, the space to explore is very large, so there is a chance the relevant portions of the full posterior distribution will rarely be explored. This is known as the curse of dimensionality.
A common way to get around this problem is to adopt a more efficient MCMC method: Hamiltonian or Hybrid Monte Carlo. It has high acceptance rate (close to 1), and this method is designed to explore large parameter spaces and deal with nasty degenerate distributions. This is exactly what we need. Note that it cannot deal with multimodal distribution - we will come back to this point later in this tutorial.
One of the peculiarities of HMC is that it requires gradients of the posterior with respect to the parameters of interest. In our case, we could write those analytically. But in real world problems this might be cumbersome and error-prone. Thus, we will use a powerful tool: automatic differentiation. This originates from the observation that differentiation rules are simple and can be propagated via the chain rule. If one can write the posterior distribution from elementary analytical or numerical operations, then finding the gradients is most likely a mechanical, algorithmic task that doesn’t need to be done by hand. And indeed, there are automatic differentiation packages that will go through a piece of code and infer the analytic form of the gradient from elementary functions. Autograd is one of those, and only require that you write your function (here the posterior distribution) with numpy (or rather, its wrapped version of numpy, as you can see from how we have imported numpy and autograd at the start of this notebook).
We will now ask autograd to create a function that computes the analytic gradient of our posterior distribution with automatic differentiation! At the moment, we will focus on our simplified posterior distribution and check that the HMC approach works, before moving to the full posterior distribution.
lnprob_hyperonly1_grad = grad(lnprob_hyperonly1)
We can numerically verify that it is indeed the gradient of our function:
params = np.concatenate([alphas, betas, gammas])
def fun(params):
return lnprob_hyperonly1(params)
def fun_grad(params):
return lnprob_hyperonly1_grad(params)
relative_accuracy = 0.00001
test_derivative(params, fun, fun_grad, relative_accuracy)
# Will complain if the gradient is incorrect
Of course, this gradient works for our original simplified posterior distribution, not the reparametrized one. So it will suffer from the degeneracies and multimodality we’ve already discussed. We want to avoid that and use our reparametrized posterior with the simplex-to-hypercube mapping.
If you try to apply autograd to the latter, you will get an error message saying that ‘numpy.cumprod’ is not yet implemented in autograd. This is the limitation of automatic differentiation: sometimes the operations used in a model are not supported. In our case, we can easily get around this problem by performing the change of variables manually (also explained in arxiv:1010.3436). In most cases, one can use automatic differentiation for large chunks of a model, and implement the rest by hand. Note that there are other frameworks supporting automatic differentiation. Autograd is convenient because it works on top of numpy. For large data sets and complicated likelihoods, I recommend Google’s TensorFlow. It requires rewriting some of your code in a particular format, but is incredibly powerful.
Note that autograd also allows us to extract the Hessian of our distribution of interest. We will use that to tune our HMC run and make it blazingly efficient. This is explained in arxiv:1206.1901 and also many other HMC papers.
def sublnprob_hyperonly(params):
alphas = params[0:n_mixture]
betas = params[n_mixture:2*n_mixture]
gammas = params[2*n_mixture:3*n_mixture]
xis = params[3*n_mixture:3*n_mixture+nobj]
lnlikes = np.log(alphas[None, :]) +\
lngaussian(yis[:, None], betas[None, :],
np.sqrt(gammas[None, :]**2. + sigmais[:, None]**2.))
res = - np.sum(logsumexp(lnlikes, axis=1))
if ~np.isfinite(res):
print("Infinite likelihood call with", params)
return res
def lnprob_hyperonly(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
res = sublnprob_hyperonly(
np.concatenate([alphas, params[n_mixture-1:]]))
return res
sublnprob_hyperonly_grad = grad(sublnprob_hyperonly)
sublnprob_hyperonly_hessian = hessian(sublnprob_hyperonly)
def lnprob_hyperonly_grad(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
jac = alphaszs_jacobian(alphas, zs)
subgrads = sublnprob_hyperonly_grad(
np.concatenate([alphas, params[n_mixture-1:]]))
grads = 1*subgrads[1:]
grads[0:n_mixture-1] = np.dot(jac, subgrads[0:n_mixture])
if np.any(~np.isfinite(grads)):
print("Infinite likelihood gradient call with", params)
return grads
def lnprob_hyperonly_hessian(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
jac = alphaszs_jacobian(alphas, zs)
subhess = sublnprob_hyperonly_hessian(
np.concatenate([alphas, params[n_mixture-1:]]))
subhessdiag = np.diag(subhess)
hess = 1*subhessdiag[1:]
hess[0:n_mixture-1] = np.diag(
np.dot(np.dot(jac,subhess[0:n_mixture, 0:n_mixture]), jac.T))
if np.any(~np.isfinite(hess)):
print("Infinite likelihood hessian call with", params)
return hess
params = np.concatenate([zs, betas, gammas])
def fun(params):
return lnprob_hyperonly(params)
def fun_grad(params):
return lnprob_hyperonly_grad(params)
relative_accuracy = 0.0001
test_derivative(params, fun, fun_grad, relative_accuracy, superverbose=False)
def fun_hess(params):
return lnprob_hyperonly_hessian(params)
relative_accuracy = 0.001
test_derivative(params, fun, fun_hess, relative_accuracy, superverbose=False, n=2)
Running HMC on the simplified posterior
The code below is an implementation of the classic HMC algorithm with bounds and a mass matrix. It is not parallelized, so we expect it will be slower than emcee. All the HMC runs below will take a few minutes to complete. However, by using analytic derivatives and Hessians, we should hope that it performs well and samples the target distribution very well. We will use random step sizes and lengths, too. Those technical choices are fairly common and discussed in Neal (2006).
The mass matrix is important in HMC, because it informs the sampler of the dimensions of the various parameters, and how constrained they are, so that the random moves are made in the most efficient directions. The most efficient choice for the mass matrix is to use the inverse hessian at the parameter optimum (i.e., the covariance matrix of the parameters). In our case we will also update the Hessian every 500 iterations, evaluated at the posterior mean. This tends to work better (than finding the optimum and computing the Hessian once) for nasty distributions.
Because this approach tells the algorithm about the local curvature, it will implicitly restrict the sample to a single mode in the posterior distribution.
Note that our sampler will throw a warning every time it rejects a sample (which is possible due to numerical approximations involved in the HMC algorithm). But this will be very rare; our acceptance rate will be very close to one.
# This is the function that performs one HMC sample,
# with num_steps steps of size step_size relative to the gradient.
# x0 is the initial point, lnprob the posterior distribution, lnprobgrad is gradients.
def hmc_sampler(x0, lnprob, lnprobgrad, step_size,
num_steps, inv_mass_matrix_diag=None, bounds=None, kwargs={}):
if bounds is None:
bounds = np.zeros((x0.size, 2))
bounds[:, 0] = 0.001
bounds[:, 1] = 0.999
if inv_mass_matrix_diag is None:
inv_mass_matrix_diag = np.repeat(1, x0.size)
inv_mass_matrix_diag_sqrt = np.repeat(1, x0.size)
else:
assert inv_mass_matrix_diag.size == x0.size
inv_mass_matrix_diag_sqrt = inv_mass_matrix_diag**0.5
v0 = np.random.randn(x0.size) / inv_mass_matrix_diag_sqrt
v = v0 - 0.5 * step_size * lnprobgrad(x0, **kwargs)
x = x0 + step_size * v * inv_mass_matrix_diag
ind_upper = x > bounds[:, 1]
x[ind_upper] = 2*bounds[ind_upper, 1] - x[ind_upper]
v[ind_upper] = - v[ind_upper]
ind_lower = x < bounds[:, 0]
x[ind_lower] = 2*bounds[ind_lower, 0] - x[ind_lower]
v[ind_lower] = - v[ind_lower]
ind_upper = x > bounds[:, 1]
ind_lower = x < bounds[:, 0]
ind_bad = np.logical_or(ind_lower, ind_upper)
if ind_bad.sum() > 0:
print('Error: could not confine samples within bounds!')
print('Number of problematic parameters:', ind_bad.sum(),
'out of', ind_bad.size)
return x0
for i in range(num_steps):
v = v - step_size * lnprobgrad(x, **kwargs)
x = x + step_size * v * inv_mass_matrix_diag
ind_upper = x > bounds[:, 1]
x[ind_upper] = 2*bounds[ind_upper, 1] - x[ind_upper]
v[ind_upper] = - v[ind_upper]
ind_lower = x < bounds[:, 0]
x[ind_lower] = 2*bounds[ind_lower, 0] - x[ind_lower]
v[ind_lower] = - v[ind_lower]
ind_upper = x > bounds[:, 1]
ind_lower = x < bounds[:, 0]
ind_bad = np.logical_or(ind_lower, ind_upper)
if ind_bad.sum() > 0:
print('Error: could not confine samples within bounds!')
print('Number of problematic parameters:', ind_bad.sum(),
'out of', ind_bad.size)
return x0
v = v - 0.5 * step_size * lnprobgrad(x, **kwargs)
orig = lnprob(x0, **kwargs)
current = lnprob(x, **kwargs)
if inv_mass_matrix_diag is None:
orig += 0.5 * np.dot(v0.T, v0)
current += 0.5 * np.dot(v.T, v)
else:
orig += 0.5 * np.sum(inv_mass_matrix_diag * v0**2.)
current += 0.5 * np.sum(inv_mass_matrix_diag * v**2.)
p_accept = min(1.0, np.exp(orig - current))
if(np.any(~np.isfinite(x))):
print('Error: some parameters are infinite!',
np.sum(~np.isfinite(x)), 'out of', x.size)
print('HMC steps and stepsize:', num_steps, step_size)
return x0
if p_accept > np.random.uniform():
return x
else:
if p_accept < 0.01:
print('Sample rejected due to small acceptance prob (', p_accept, ')')
print('HMC steps and stepsize:', num_steps, step_size)
#stop
return x0
num_samples, burnin = 10000, 2000
params = np.concatenate([zs, betas, gammas])
bounds = np.zeros((params.size, 2))
bounds[:, 0] = 0.0
bounds[:, 1] = 1.0
param_samples_hyperonly = np.zeros((num_samples, params.size))
param_samples_hyperonly[0, :] = params
hess = np.abs(lnprob_hyperonly_hessian(params))
for i in range(1, num_samples):
step_size = np.random.uniform(1e-3, 1e-1)
num_steps = np.random.randint(2, 10)
if i % 500 == 0:
print(i, end=" ")
newparams = np.mean(param_samples_hyperonly[0:i-1, :], axis=0)
hess = np.abs(lnprob_hyperonly_hessian(newparams))
param_samples_hyperonly[i, :] =\
hmc_sampler(param_samples_hyperonly[i-1, :],
lnprob_hyperonly, lnprob_hyperonly_grad,
step_size, num_steps,
bounds=bounds, inv_mass_matrix_diag=1./hess)
param_samples_hyperonly = param_samples_hyperonly[burnin:, :]
_ = corner.corner(param_samples_hyperonly, truths=params, labels=param_names)
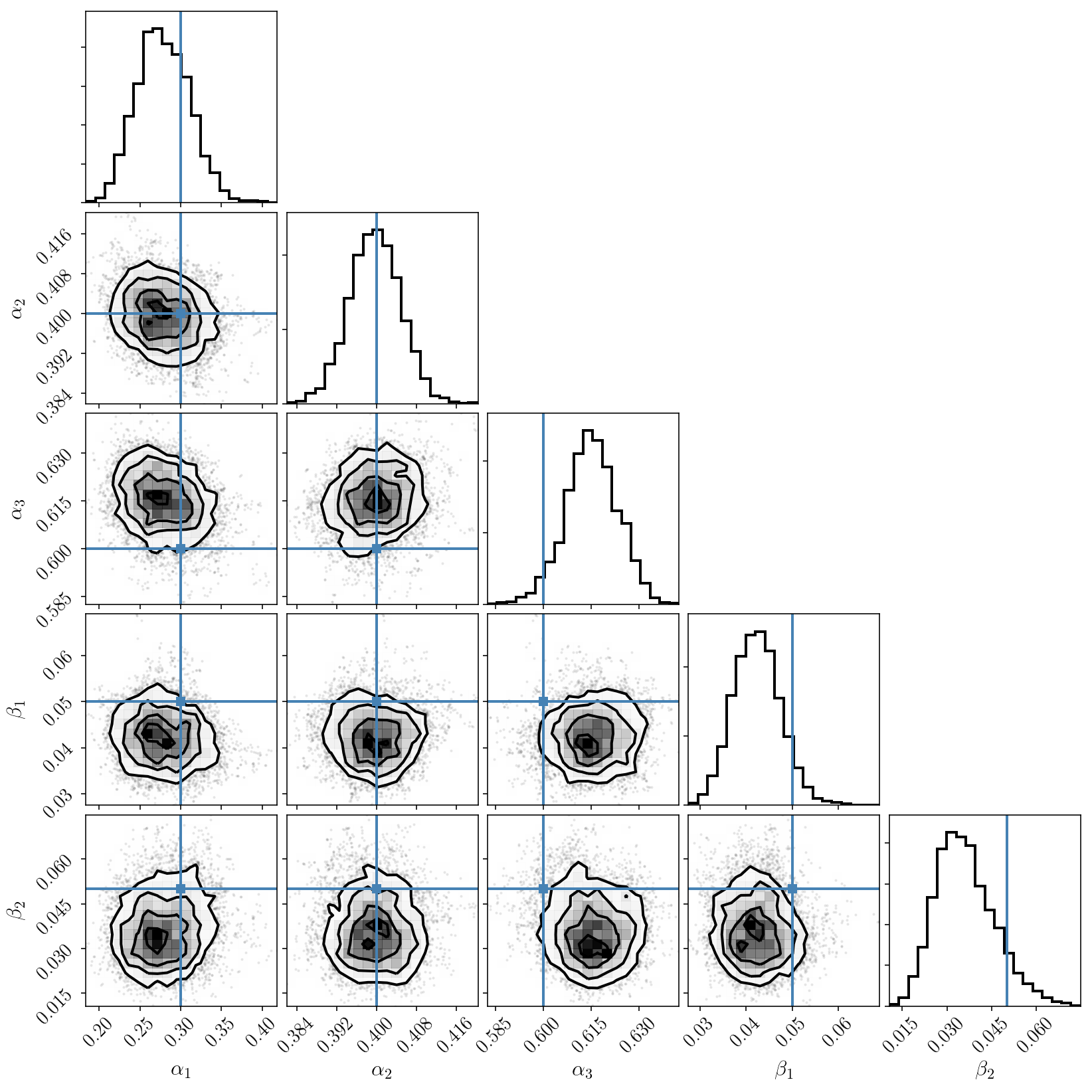
The marginalized posterior distribution for pairs of parameters looks good. Let’s look at the marginalized posterior for the individual parameters and compare with the results we obtained with emcee.
fig, axs = plt.subplots(2, 3, figsize=(11, 5))
axs = axs.ravel()
for i in range(5):
axs[i].hist(param_samples_hyperonly[:, i], histtype='step', normed=True, label='HMC')
rr = axs[i].get_xlim()
axs[i].hist(sampler.flatchain[:, i], range=rr,
histtype='step', normed=True, label='emcee')
axs[i].axvline(params[i], c='b', label='truth')
axs[i].set_xlabel(param_names[i])
axs[-3].legend(frameon=True, loc='upper right')
plt.delaxes(axs[-1])
fig.tight_layout()
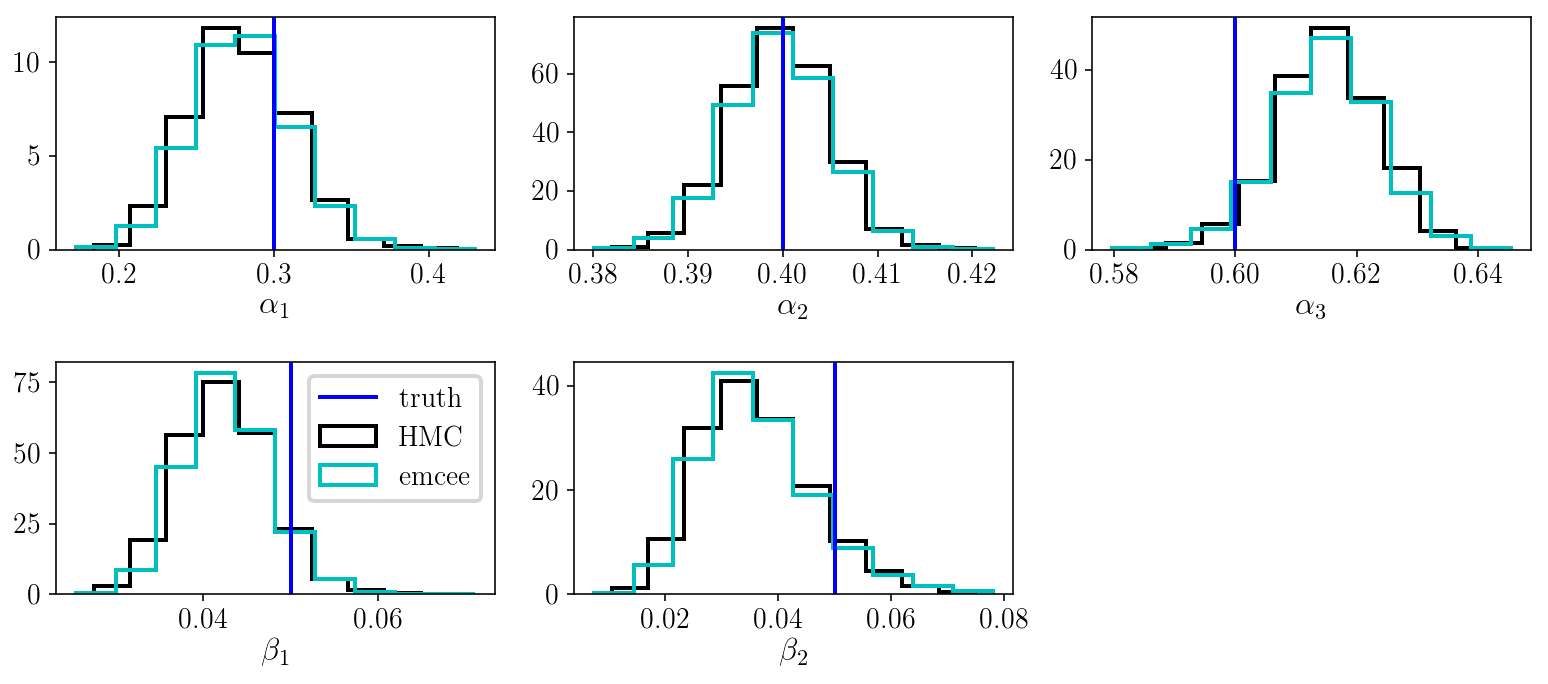
As we can see, the HMC run was successful, which is good! However, it is slower than emcee. This is because, despite using gradient information to obtain a higher acceptance rate (close to 1, as opposed to 0.3), our HMC sampler is not parallelized. And emcee is generally blazingly fast. We could make HMC much more efficient if we wanted.
However, we will now sample the full posterior distribution, which emcee cannot deal with since it has way too many parameters.
Sampling the full posterior distribution with latent variables
We will now sample
\[p(\vec{f},\vec{\beta}, \vec{\gamma}, \{ x_i \} \vert \{y_i, \sigma_i\})\propto p(\vec{f},\vec{\beta}, \vec{\gamma}) \prod_{i=1}^N \sum_{b=1}^B f_b \mathcal{N}(x_i\vert \beta_b,\gamma^2_b)\mathcal{N}(y_i\vert x_i,\sigma^2_i)\]using HMC with the settings described before.
def sublnprob_withxis(params):
alphas = params[0:n_mixture]
betas = params[n_mixture:2*n_mixture]
gammas = params[2*n_mixture:3*n_mixture]
xis = params[3*n_mixture:3*n_mixture+nobj]
lnlikes = np.log(alphas[None, :]) +\
lngaussian(xis[:, None], betas[None, :], gammas[None, :]) + \
lngaussian(yis[:, None], xis[:, None], sigmais[:, None])
res = - np.sum(logsumexp(lnlikes, axis=1))
if ~np.isfinite(res):
print("Infinite likelihood call with", params)
return res
def lnprob_withxis(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
res = sublnprob_withxis(np.concatenate([alphas, params[n_mixture-1:]]))
return res
sublnprob_withxis_grad = grad(sublnprob_withxis)
sublnprob_withxis_hessian = hessian(sublnprob_withxis)
def lnprob_withxis_grad(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
jac = alphaszs_jacobian(alphas, zs)
subgrads = sublnprob_withxis_grad(
np.concatenate([alphas, params[n_mixture-1:]]))
grads = 1*subgrads[1:]
grads[0:n_mixture-1] = np.dot(jac, subgrads[0:n_mixture])
if np.any(~np.isfinite(grads)):
print("Infinite likelihood gradient call with", params)
return grads
def lnprob_withxis_hessian(params):
zs = params[0:n_mixture-1]
betas = params[n_mixture-1:2*n_mixture-1]
gammas = params[2*n_mixture-1:3*n_mixture-1]
alphas = zs_to_alphas(zs)
jac = alphaszs_jacobian(alphas, zs)
subhess = sublnprob_withxis_hessian(
np.concatenate([alphas, params[n_mixture-1:]]))
subhessdiag = np.diag(subhess)
hess = 1*subhessdiag[1:]
hess[0:n_mixture-1] = np.diag(
np.dot(np.dot(jac, subhess[0:n_mixture, 0:n_mixture]), jac.T))
if np.any(~np.isfinite(hess)):
print("Infinite likelihood hessian call with", params)
return hess
params = np.concatenate([zs, betas, gammas, xis])
def fun(params):
return lnprob_withxis(params)
def fun_grad(params):
return lnprob_withxis_grad(params)
# Numerically test the gradient
relative_accuracy = 0.001
test_derivative(params, fun, fun_grad, relative_accuracy, superverbose=False)
def fun_hess(params):
return lnprob_withxis_hessian(params)
# Numerically test the hessian
relative_accuracy = 0.001
test_derivative(params, fun, fun_hess, relative_accuracy, superverbose=False, n=2)
num_samples, burnin = 10000, 2000
params = np.concatenate([zs, betas, gammas, xis])
bounds = np.zeros((params.size, 2))
bounds[:, 0] = 0.01
bounds[:, 1] = 0.97
param_samples_withxis = np.zeros((num_samples, params.size))
param_samples_withxis[0, :] = params
hess = np.abs(lnprob_withxis_hessian(params))
for i in range(1, num_samples):
step_size = 10.**np.random.uniform(-3, -1)
num_steps = np.random.randint(5, 20)
if i % 500 == 0:
print(i, end=" ")
newparams = np.mean(param_samples_withxis[0:i-1, :], axis=0)
hess = np.abs(lnprob_withxis_hessian(newparams))
param_samples_withxis[i, :] =\
hmc_sampler(param_samples_withxis[i-1, :],
lnprob_withxis, lnprob_withxis_grad,
step_size, num_steps,
bounds=bounds, inv_mass_matrix_diag=1./hess)
param_samples_withxis = param_samples_withxis[burnin:, :]
param_names = [r'$$z_'+str(i+1)+'$$' for i in range(n_mixture-1)] +\
[r'$$\beta_'+str(i+1)+'$$' for i in range(n_mixture)] +\
[r'$$\gamma_'+str(i+1)+'$$' for i in range(n_mixture)]+\
[r'$$x_{'+str(i+1)+'}$$' for i in range(nobj)]
fig, axs = plt.subplots(5, 3, figsize=(12, 12))
axs = axs.ravel()
for i in range(axs.size):
axs[i].set_xlabel(param_names[i])
axs[i].hist(param_samples_withxis[:, i], histtype='step',
normed=True, label='Full posterior')
if i < 5:
axs[i].hist(sampler.flatchain[:, i], histtype='step',
normed=True, label='Simplified posterior')
axs[i].axvline(params[i], c='b', label='Truth')
if i >= 5:
likedraws = yis[i-5] + \
np.random.randn(param_samples_withxis[:, i].size) * sigmais[i-5]
axs[i].hist(likedraws, histtype='step',
normed=True, color='red', label='Likelihood')
if i == 6 or i == 4:
axs[i].legend(loc='upper right', frameon=True)
fig.tight_layout()
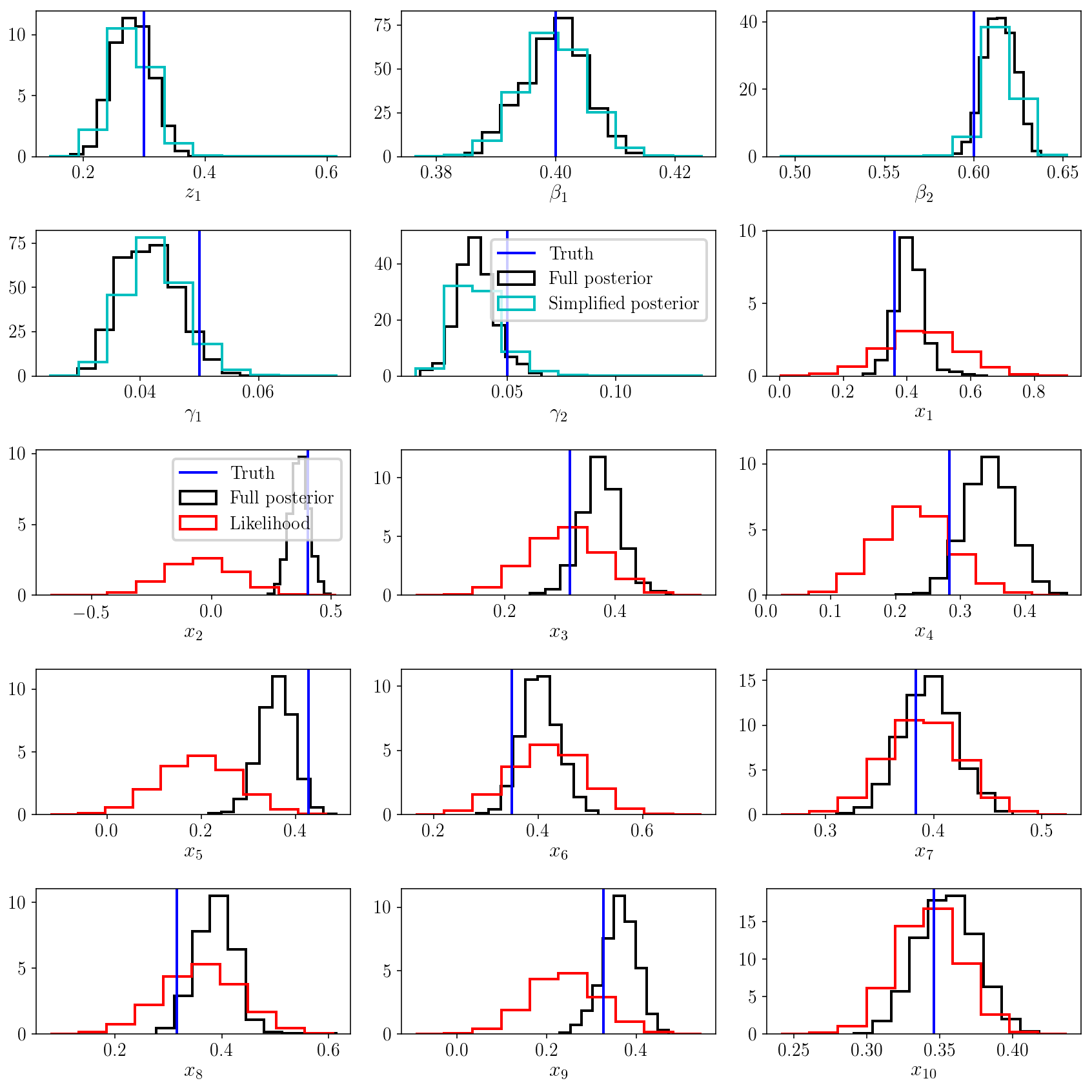
The marginalized posterior distribution looks good. For the population parameters \(\vec{z}, \vec{\beta}, \vec{\gamma}\), it matches what we obtained with the simplified posterior distribution. This is remarkable because we have added a ton of parameters to the model, and explored a much bigger parameter volume. Thanks to HMC, this exploration was efficient, and we were able to numerically marginalize over all the latent variables \(x_i\)’s and recover the results from the analytic solution, the simplified posterior distribution.
Hierarchical uncertainty shrinkage
The other panels in the figure above show a comparison of the posterior distribution on each \(x_i\) versus the likelihood function \(p(y_i \vert x_i)\). This is a typical illustration of Bayesian shrinkage: by fitting a model to the population of objects, we in turn improve the individual estimates. It doesn’t matter that those parameters are latent - they are connected via a hierarchical probabilistic model, so the information gained in one part of the model might actually affect the rest of the model. This is a theme that we have explored (and will continue to explore) in other tutorials.
Number of components and multimodality
We have not discussed a number of additional issues that may arise, including what happens if the data are very noisy and/or the components significantly overlap. Those are common with mixture models.
Indeed, those can create new degeneracies in the posterior distribution, since components can more easily be interchanged if they overlap or in the presence of significant noise. One can still find a prior that alleviates those degeneracies, but this might not be sufficient. In that case, an HMC sampler that is carefully tuned should still work. But if the distribution is really multimodal, then one could adopt a “tempered” HMC sampler. For example, the approach of https://arxiv.org/abs/1704.03338 is interesting.
(By tuning, I refer to the parameters of the HMC algorithm: the step size, number of steps, and mass matrix. There is a lot of litterature on how to tune this to make the exploration of complicated posterior distribution more efficient. In particular, one wants an acceptance rate close to one, and the maximum step size and minimum number of steps that yield to a good MCMC chain. A good metric for that is the correlation between samples - we want samples that are as independent as possible, and fully explore the posterior distribution.)
Another related question is how to find a suitable prior to alleviate labelling degeneracies in \(>1\) dimensions. This is possible, but may require some careful thinking. Again, the key is to order the components in a quasi-unique fashion.
But the most critical question we have not mentioned so far is the choice of number of components. In most real-world problems, one does not know how many components to use. This is a vast, deep question which is addressed in countless papers, many of them beyond the scope of this tutorial. The classical approach boils down to doing multiple runs with different number of components, and performing model selection (in a Bayesian fashion) or cross-validation (in a frequentist fashion) to select the best number of components. Indeed, the denominator of our full posterior distribution (neglected previously) is the evidence
\[E = p( \{y_i, \sigma_i\}) = \int p(\vec{f},\vec{\beta}, \vec{\gamma}, \{ x_i \} \vert \{y_i, \sigma_i\}) \mathrm{d} \vec{f} \mathrm{d}\vec{\beta} \mathrm{d} \vec{\gamma} \mathrm{d} \{ x_i \}\]In other words, one way or another, a huge multidimensional integral is needed. Calculating evidences accurately is a research topic on its own. One can run a very long MCMC chain and perform this integral numerically. Or adopt a more adequate sampler that explicitly targets the evidence (e.g., via nested sampling). Those options are good. For two runs with two different numbers of components \(B_1\) and \(B_2\), the evidence ratio (also called Bayes factor) will allow one to perform model selection and pick the preferred number of components. Even better, one could simply consider both models simultaneously, and weight the samples in each model by their respective evidences. All of those could be performed with nested sampling.
Note that with mixture models, we are in a very particular situation: by fixing one or multiple \(z_i\) or \(\alpha_i\) to zero or one, the number of components has effectively changed. We say that the models are nested. Nested models are very convenient and are worth learning about. Many physical models are nested, and this hugely simplifies model comparison, via the Savage Dickey density ratio, for example.
Equivalently, one could adopt a trans-dimensional approach and explore the space of models with a variable number of components. It is in fact equivalent to multiple-run solution we just discussed. Either way, there are various pieces of technology to achieve that, such as trans-dimensional MCMC (which explicitely adds and removes parameters), which we will not discuss here. But you should immediatly spot that we have already done that: when we ran nested sampling with three components, we found that the posterior distribution was naturaly peaked at two components, with the third one often set to zero. The point is: for nested models, it is not that hard to perform a trans-dimensional sampling. One only needs to write the posterior distribution in a convenient, nested form, and think carefully about what priors would help pinning down (i.e., sampling) the most probably number of components.
This brings us to our final point of discussion and experiment.
Interpretability of mixture models.
Let’s run PolyChord with more components - say four - and show the result in data space, i.e., plot the true density of objects and that infered with our Gaussian mixture model.
code4 = """
PolyChord.run_nested_sampling(mixturemodellnprob, ndim, nderived, prior=prior,
file_root='mixturemodellnprob', do_clustering=False,
nlive=50*ndim, update_files=50*ndim,
num_repeats=5*ndim, boost_posterior=1)
"""
n_mixture2 = 4
text_file = open("run_PyPolyChord.py", "w")
text_file.write(code1 % n_mixture2 + code4)
text_file.close()
# go in the terminal and run
# rm -rf chains ; mkdir chains ; mkdir chains/clusters ; python run_PyPolyChord.py
# If you get a segmentation fault, you'll need to compile PolyChord with extra flags
# to make sure the stack size is sufficient.
samples = np.genfromtxt('chains/mixturemodellnprob_equal_weights.txt')[:, 2:]
print(np.min(samples, axis=0))
fig, axs = plt.subplots(2, 2, figsize=(10, 6), sharex=True, sharey=True)
axs = axs.ravel()
for i in np.random.choice(samples.shape[0], 200, replace=False):
alphas2 = zs_to_alphas(samples[i, 0:n_mixture2-1])
alphas2 /= alphas2.max()
j = np.sum(alphas2 > 0.1) - 1
alphas2 /= alphas2.sum()
betas2 = samples[i, n_mixture2-1:2*n_mixture2-1]
gammas2 = samples[i, 2*n_mixture2-1:3*n_mixture2-1]
p_x_grid2 = alphas2[None, :] *\
np.exp(-0.5*((x_grid[:, None] - betas2[None, :])/gammas2[None, :])**2)/\
np.sqrt(2*np.pi)/gammas2[None, :]
p_x_grid2 = np.sum(p_x_grid2, axis=1)
#p_x_grid2 /= p_x_grid2.max() / p_x_grid.max()
axs[j].plot(x_grid, p_x_grid2, color='r', alpha=0.2, lw=1)
for j in range(4):
#axs[j].plot(x_grid, p_x_grid[:, :].sum(axis=1), c='k')
axs[j].set_title(str(j+1)+' components')
axs[j].hist(xis, histtype='step', normed=True)
axs[j].hist(yis, histtype='step', normed=True)
axs[0].set_xlim([0, 1])
axs[0].set_ylim([0, np.max(p_x_grid)*1.3])
axs[-1].set_xlabel(r'$$x$$')
axs[-2].set_xlabel(r'$$x$$')
fig.tight_layout()
[ 1.86289840e-01 1.74044470e-05 2.52719810e-05 3.81298540e-01
2.86397260e-01 5.80634280e-04 4.93057490e-04 3.00007840e-02
3.00022170e-02 3.00227310e-02 3.00666050e-02]
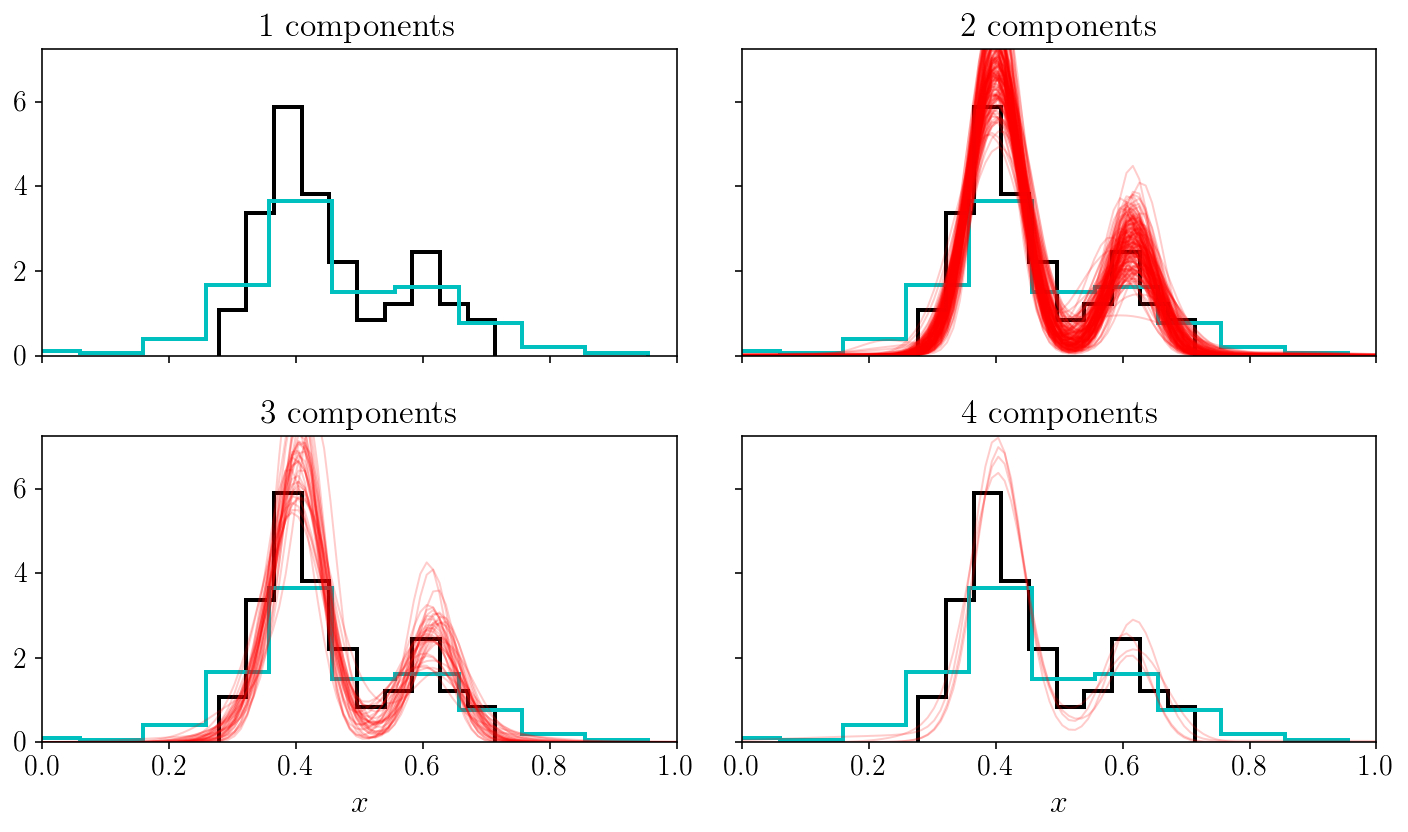
In this figure, we have separated the models into their number of components (specifically: any component having an amplitude ten times smaller than the largest component is not counted). Since we randomly picked posterior stamples, the number of curves arriving in each subpanel is also telling us something about the most probably number of components. In fact, we could relate those relative densities to Bayes factors for the nest models with 1, 2, 3 and 4 components. What we are doing is much more generic and straightforward: we have implicitly performed a trans-dimensional sampling since we have allowed some of the compoments to be zero.
One final comment: you can see that except for the one-component case, most of our model samples indeed capture the true bimodal nature of the density. However, why are some of those models made of three and four components? This happens because we have not restriced the components to overlap. This creates yet another degeneracy on top of the labeling one: the fact that any component can be decomposed into sub-components with lower amplitudes. When considering a larger space of models (i.e., trans-dimensional), this is a complicated problem. This is related to the interpretability of mixture models. Luckily for us, it can be solved in two ways: in a fully Bayesian inference setting like we described in this tutorial, one can easily adopt a prior that mitigates this effect, for instance by forcing the components to be separated by some amount. An alternative which is particularly popular in the realm of empirical Bayesian inference and maximum a-posteriori solutions (i.e., finding the optimum of the posterior distribution only) is a set of “split and merge” methods, allowing to litteraty split and merge some of the components when relevant. The paper about extreme deconvolution by Bovy et al (2009) is a good place to learn about that.
If we adopt a large number of components, what do you think will happen? The answer is simple: the components will position themselves at the location of the true values \(x_i\). The phenomenon is known as mode collapse. Worse, the \(x_i\)’s are latent variables, the collapsed components will never properly converge. Another final comment: if the number of objects is large and the gradients intensive to compute, standard HMC might be less compelling. Luckily, there is a natural solution to this issue: not using all of the data when calculating the gradient. However, a naive implementation of this idea is not recomment. Indeed, it has been shown by https://arxiv.org/abs/1402.4102 that this can yield arbitrarily bad results. The correct approach is presented in that same paper: the HMC must include an extra term to capture the extra noise introduced by the approximate gradient. This idea works beautifully well, even on large models and data sets, such as deep neural networks.